Machine Learning
As mentioned in the article „Motivation“, due to the technical development in the field of IT as well as in the field of mobile communication and the further interconnection of our world, human kind faces an era hallmarked by the omnipresence of data.
In the years to come, an increasing number of products supporting people for new or already known purposes will be connected to the internet and exchanging data with other “things” in the growing network. Beside the challenge to find a reasonable way to process the data out of a hardware-performance and IT-architectural perspective, it is necessary to find a way to take advantage of this data.
Traditional algorithms are providing an intelligent behaviour to the programs they are embedded in. To give them this characteristic, developers create complex networks of decision rules and actions to ensure that the machine is acting in a smart manner within the usecases of the product. As you might imagine, the amount of possible usecases dependent on the product is quite big and the effort to cover all possible usecases with traditional algorithms is either quite high.
With this in mind, it seems to be quite logic that the complexity and with that the vulnerability to bugs is increasing when the amount of data grows.
Imagine that you have to solve the task to predict the name of respective fruits based on their properties such as “water content”, “color”, “form”, “pipfruit”, “thickness of the peel”, “citrus fruit yes/no” and “growing region”. With a traditional algorithm it would be much work to come to a result nesting countless if-clauses and loops. And even if you come to an acceptable result, the maintenance of such a manually implanted algorithm would be very high because in a dynamic world new data and with that new expressions of the variables like for example “thickness of the peel” or “color” etc. are generated in the underlying data and for a good functioning system you have to consider this new expressions also in your algorithm.
Definition Machine Learning
So, wouldn’t it be fairly desirable, if the algorithm learns the task to classify the fruits on its own?
The usecase above for example would be a perfect fit for the application of an algorithm from the maybe most prominent subfield of machine learning called supervised learning.
But what is Machine Learning concretely?
In general, Machine Learning is an own area of the superior research field Artificial Intelligence and can be seen metaphorically as a central toolbox with several intelligent algorithms that realize the property “Artificial Intelligence” for systems.
Within the field that can be understood as a form of applied statistics a computer program improves its performance on a given task or class of tasks by learning from experience while training on the latter.
Definition Machine Learning
To obtain a deeper understanding, it is useful to discuss the distinct categories of Machine Learning. I forgo an exhaustive consideration of all existent categories, but I will take a closer look at the main categories of Machine Learning.
In general, it is possible to classify three main types in Machine Learning:
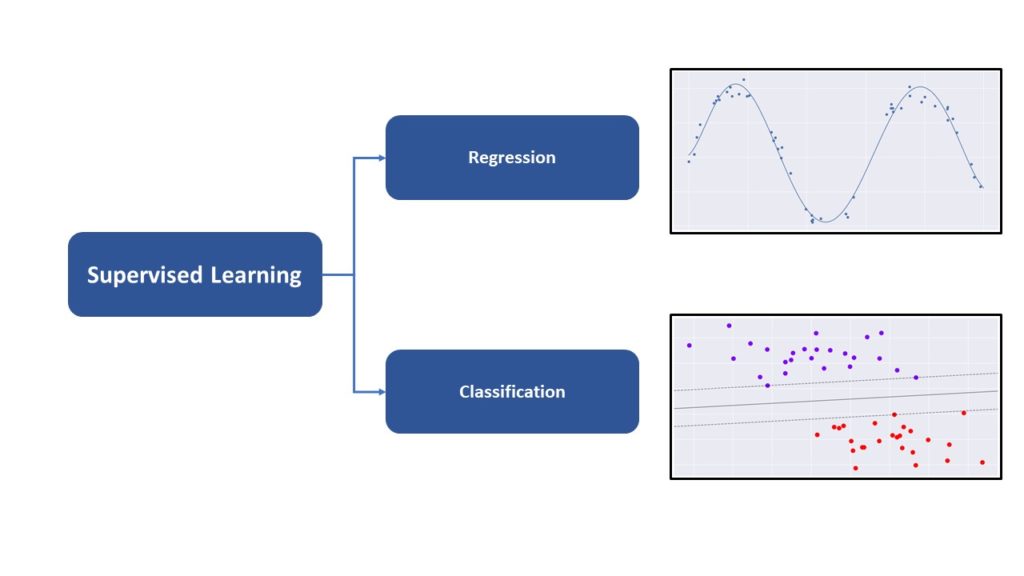
- Supervised Learning: Learning with a teacher a specific task (task-focus)
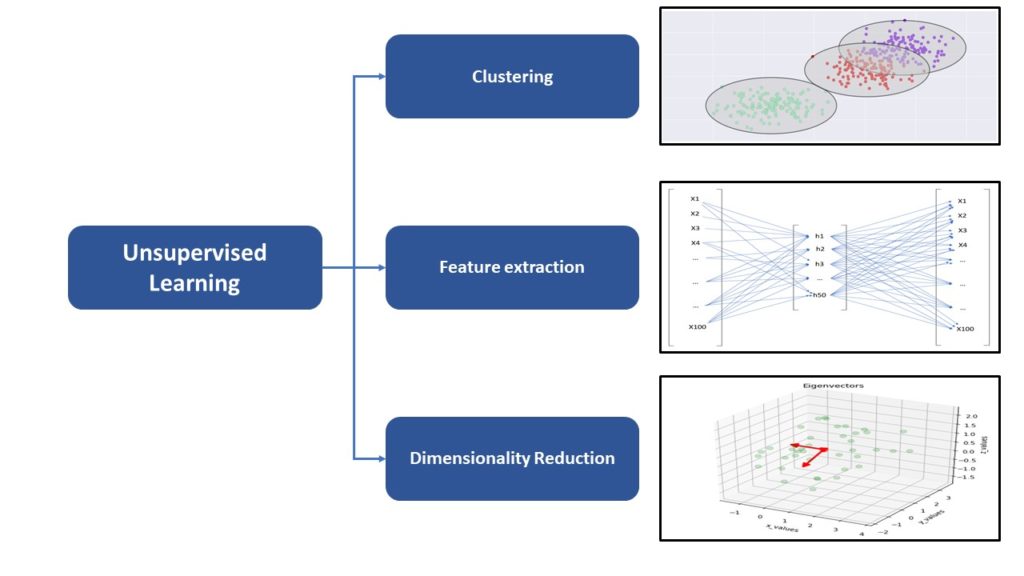
- Unsupervised Learning: Recognizing patterns without a teacher (data focus)
- Reinforcement Learning: Learning from own mistakes (exploration focus)
In the following, I will describe the three categories respectively in more detailed manner.
Supervised Learning
Remember your childhood. You went into town to take a walk by the shopping streets with your parents. You saw another family with a big dog, a german shepherd, crossing your way. You said to your dad: “Look daddy, a cat!” Your dad answered: “No, you’re mixing up sweety. A cat isn’t big as that. This is a dog. Like in your little book we’re reading every evening.” You took another close look and tried to remember the size and the physiognomy of the animal. Two hours later, you cross another dog, a Chihuahua, and you look at your mother: “But this is a cat, huh mummy? He is so tiny” “Haha, you’re right for the size, but actually this is also a little dog, my dear. You can recognize them by the pointed muzzle.” Again, you tried to remember the physiognomy of this animal, memorized it and assign it to the breed “dog”. Imagine this little sequence out of your life repeating itself again and again over time. Every time you cross an animal you asked your parents what you suppose this animal to be and your parents give you the right answer. Either you guessed correctly and you’re satisfied or you guessed not correctly and you’ve to adapt your vision of the appearance of the concerning animal to have a better guess the next time. While this training with your teachers, in this usecase your parents, you got better and better over time. Finally, you ended up being perfectly able to distinguish a dog from a cat and the other animals without help of your teachers – just thanks to your training.
In supervised learning the same concept is applied. The algorithm is trained on the specific data of the underlying task and tries hereby, given a certain input vector consistent of nominal or numerical variables, to predict an output. This estimated output is then compared to the real output of the training data linked with the input vector. In case of a misprediction the weights within the algorithms are updated following a certain logic, e.g. Gradient Descent, to optimize the capacity of the algorithm to generalise on the specific task. Generalising means in this context that the algorithm depicts the statistical relationship between the input vector and the output in a satisfactory way.
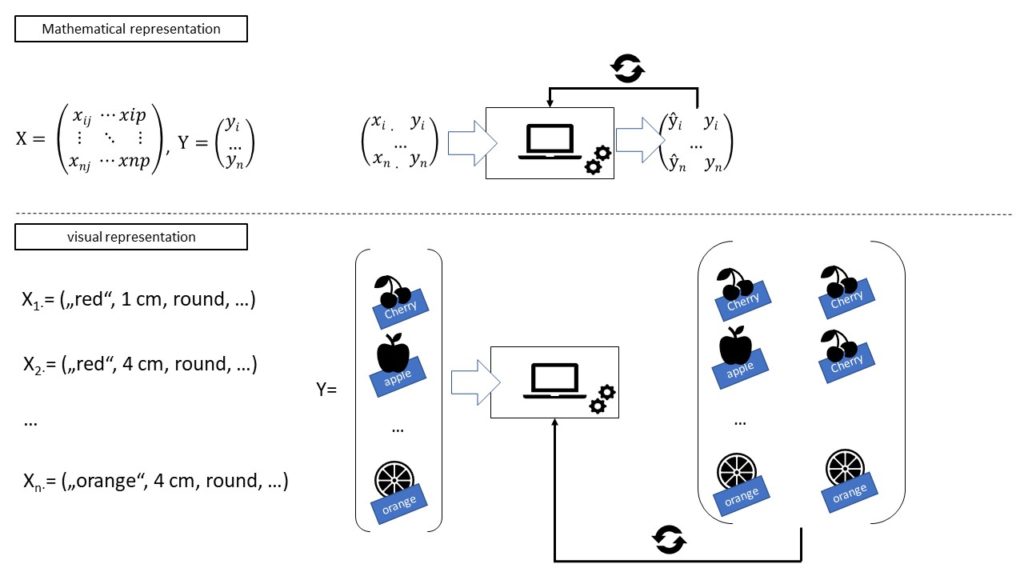
Unsupervised Learning
Unlike the more popular subfield Supervised Learning, unsupervised Learning, as one might deduct from the name, describes a type of algorithms where the machine doesn’t learn with a teacher – so the correct answers to the task isn’t available for training.
The goal of this kind of algorithms is to find (useful) patterns in the data such as regularities, irregularities, similarities and other relationships on its own. Hereby, the statistical properties of the unlabelled data as well as the other measures e.g. euclidean distances come into play finding a reasonable way to cluster or to describe the data. Unsupervised learning algorithms are learning the structure of the underlying data and retaining it to label new data into distinct groups. Regarding the dimension of the data, in unsupervised learning the observation data is in some cases much higher and more complex than in supervised learning. This is because in unsupervised learning there is no need to infer a connection between to data sets which is a task increasing exponentially in difficulty with growing dimensionality. Often supervised learning is preceded by unsupervised learning to label data which isn’t available with a clear classification.
You can distinguish in general between three types of algorithms:
- Clustering: Cluster-Algorithms try to discover patterns in the data which could be useful for grouping It into distinct categories. A popular representative of this family of algorithms would be the k-means algorithm.
- Dimensionality Reduction: Algorithms such as t-SNE transform the original high-dimensional data into a lower dimensioned space in order to assure that only useful features/variables last in the dataset. In this way, a following clustering is far easier if it’s still necessary and the most important features are chosen for further proceedings (e.g. supervised learning).
- Feature extraction:Feature extraction hits a bit the same road as dimensionality reduction because it is possible to reduce the features of the dataset to the most important ones to describe it. In addition to that new feature combination e.g. with auto-encoding can be found and used in further ML algorithms.
And this paradigm isn’t limited to the smart home, but ranging from smart infrastructure, smart farming to smart cities and much more.
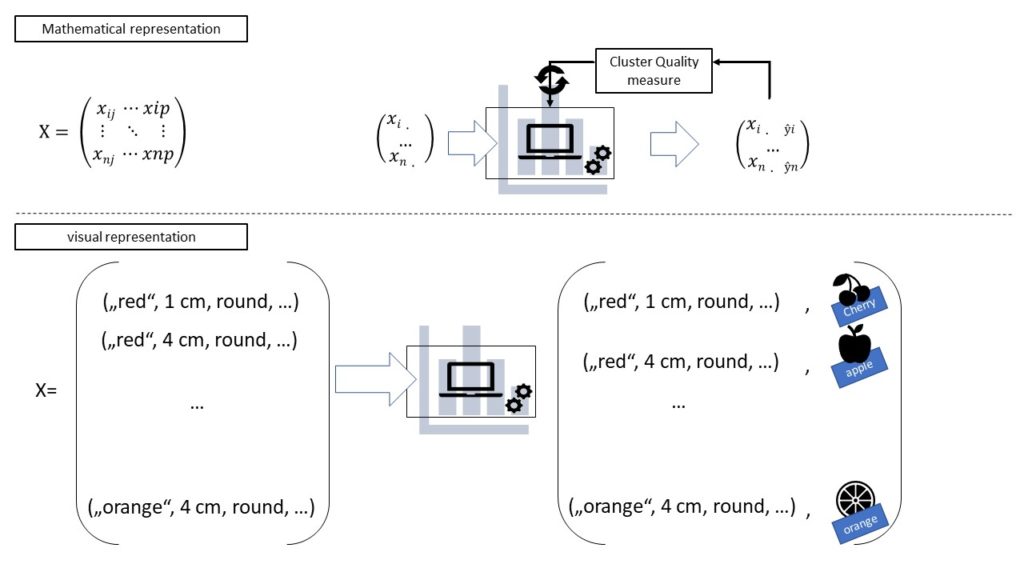
Reinforcement Learning
The third family of generic Machine Learning algorithm is Reinforcement Learning. While supervised learning algorithms are learning their task with a teacher and the unsupervised learning ones are discovering interesting, hidden structures in the data without a teacher, reinforcement learning algorithm are learning from their own experience.
As you can observe in the video above, the agent, in this case the robot, is equipped with an arm which he is able to move by positioning two servo-motors and his goal is it to move forward. At first in the training phase, he is quite clueless how to fulfil this goal, but he begins as every human would begin by trying a random action and evaluate the situation afterwards. After that he’s trying another movement and after that another until he finally finds the right way to move efficiently forward.
With this example in mind, it is now easier to give a definition of Reinforcement Learning and its functioning.
In Reinforcement Learning, an agent is confronted with a task or multiple tasks to solve on its own by figuring out the best way to handle it drawing on his own experience. Hereby the agent interacts with
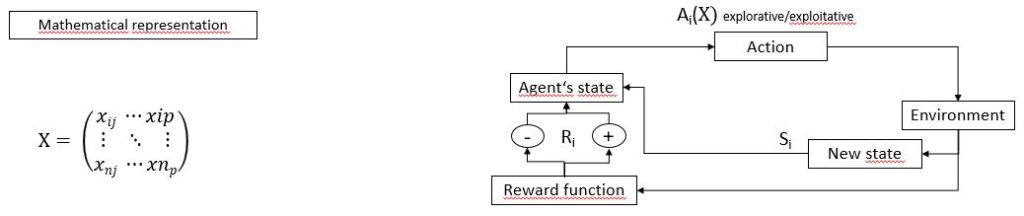
the environment by taking action Ai randomly or on purpose which has an effect on its environment and changes the state Si of the agent. The result of the Ai is then evaluated by a reward function transmitting the information to the agent if the action taken should be further exploited or if the strategy has to be adapted. The goal is it to maximize the reward function.
After this detailed introduction to of Machine Learning, the reader obtained a solid understanding of the central paradigms of the field. To further complete this understanding, it is meaningful to dive now into the superior research area Artificial Intelligence.
Sources
- Brownlee, Jason (2016): Supervised and Unsupervised Machine Learning Algorithms. Hg. v. MaschineLearningMastery.com. Online verfügbar unter https://machinelearningmastery.com/supervised-and-unsupervised-machine-learning-algorithms/.
- Garcia, Salvador; Luengo, Julian; Herrera, Francisco; García, Salvador; Luengo, Julián (2015): Data Preprocessing In Data Mining. Cham, Heidelberg, New York, Dordrecht, London: Springer Vieweg; Springer (Intelligent systems reference library, Volume 72).
- Gläß, Rainer (2018): Künstliche Intelligenz im Handel 1. Digitale Komplexität managen und Entscheidungen unterstützen. Wiesbaden: Springer Vieweg (essentials).
- Goodfellow, Ian; Bengio, Yoshua; Courville, Aaron (2016): Deep Learning. Hg. v. MIT Press. Online verfügbar unter http://www.deeplearningbook.org, zuletzt geprüft am 20.06.2019.
- Hastie, Trevor; Tibshirani, Robert; Friedman, Jerome H. (2017): The elements of statistical learning. Data mining, inference, and prediction. Second edition, corrected at 12th printing 2017. New York, NY: Springer (Springer series in statistics).
- Isha, Salian (2018): SuperVize Me: What’s the Difference Between Supervised, Unsupervised, Semi-Supervised and Reinforcement Learning? Hg. v. Nvidia. Online verfügbar unter https://blogs.nvidia.com/blog/2018/08/02/supervised-unsupervised-learning/, zuletzt aktualisiert am 02.08.2018.
- Marsland, Stephen (2015): Machine learning. An algorithmic perspective. Second edition. Boca Raton, FL: CRC Press (Chapman & Hall / CRC machine learning & pattern recognition series).
- Mitchell, Tom M. (2010): Machine learning. International ed. New York, NY: McGraw-Hill (McGraw-Hill series in computer science).
- Patel, Ankur A.: Chapter 1. Unsupervised Learning in the Machine Learning Ecosystem. Online verfügbar unter https://www.oreilly.com/library/view/hands-on-unsupervised-learning/9781492035633/ch01.html.
- Sutton, Richard S.; Barto, Andrew (2018): Reinforcement learning. An introduction. Second edition. Cambridge, MA, London: The MIT Press (Adaptive computation and machine learning).
